Today, we’re diving into something truly amazing that Google’s researchers have cooked up. They’ve cracked the code on copying voices and making them speak different languages, even if the original speaker doesn’t know those languages. It’s called “zero-shot cross-lingual voice transfer for text-to-speech,” but don’t let that mouthful scare you off. We’re going to break it down and see why it’s such a big deal.
The Voice Restoration Revolution
Imagine getting your voice cord damaged due to an illness or injury. Pretty scary, right? Now, picture getting it back, but with superpowers – you can speak any language you want! That’s exactly what Google’s new tech is aiming to do. It’s like giving someone their voice back, but with an extra sprinkle of magic.
how does ai voice cloning work?
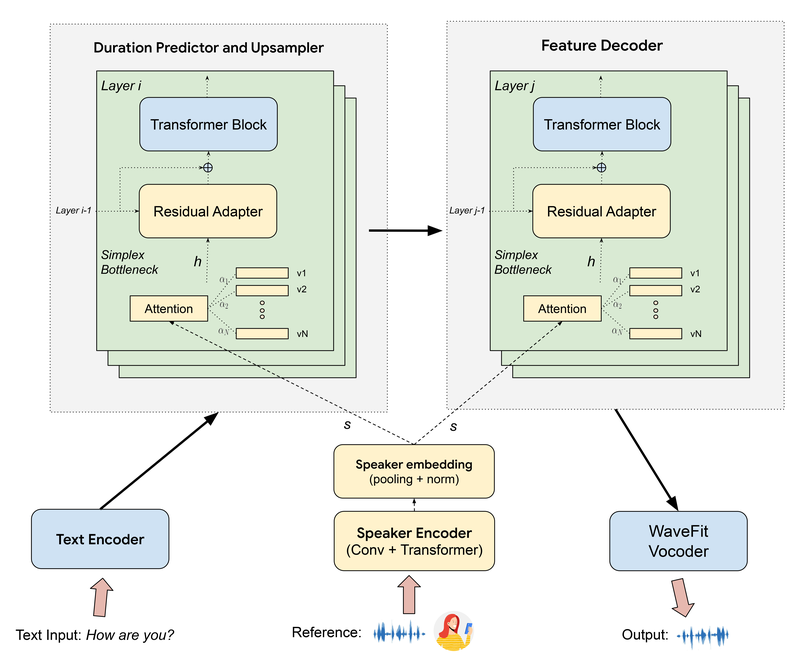
This image is a diagram illustrating a neural network architecture for a text-to-speech (TTS) system.
Overall Flow:
- Text input is encoded into a format suitable for TTS processing by the Text Encoder.
- Reference audio is processed by the Speaker Encoder to extract speaker-specific features.
- These encoded inputs are fed into the Duration Predictor and Upsampler to generate a detailed speech representation.
- This representation is then refined by the Feature Decoder.
- Finally, the WaveFit Vocoder generates the final audio output that sounds like the reference speaker, saying the input text.
summary
- Voice Copying (or “Voice Conversion”): The system listens to someone’s voice and learns to mimic it. It’s like having a super-smart parrot that can copy not just words, but the whole way you speak.
- Language Switching (or “Cross-Lingual Transfer”): Once it’s learned your voice, it can use that voice to speak in different languages. It’s like if you suddenly woke up able to speak perfect Chinese or Arabic!
- Quick Learning (“Zero-Shot Learning”): Here’s the really cool part – the system doesn’t need hours and hours of your voice or lots of examples in different languages. It can do its magic with just a little bit of your voice. It’s like it has a built-in universal translator!
Why Should We Care?
Medical Help: For folks who’ve lost their voice due to things like throat cancer or ALS (Amyotrophic lateral sclerosis), this could be a game-changer. Imagine being able to sound like yourself again, even if you can’t physically speak.
Language Learning: Want to hear how you’d sound speaking fluent Japanese? This tech could make language learning more fun and personal.
Making Content for Everyone: Imagine making videos, podcasts, or audiobooks that can speak to people all over the world, in their own languages, without needing a bunch of different voice actors.
Helping Hand for All: This could make things like talking computers and digital assistants more friendly and accessible for everyone, no matter what language they speak.
The Science Stuff (Don’t Worry, I’ll Keep It Simple)
For those who like to peek under the hood:
- Voice Encoder: This part is like a super-listener. It pays attention to what makes your voice unique – the way you pronounce things, the rhythm of your speech, the little quirks that make you sound like you.
- Multilingual Text-to-Speech Model: Think of this as the multilingual singer in the band. It knows how to “sing” in lots of different languages while keeping the “voice” the same.
- Prosody Transfer: This is the rhythm keeper. It makes sure that when the system speaks in a new language, it doesn’t sound like a robot, but keeps the natural flow and melody of speech.
The system uses some clever tricks like “self-supervised learning” (basically, it teaches itself) and “adversarial training” (it plays a game of “fool the detector” to get better). It’s like teaching a computer to be the world’s best voice impressionist!
Putting It to the Test: Real-World Experiments
Google didn’t just make this cool tech and call it a day. They put it through its paces with some impressive experiments. Let’s check them out:
The Basics: Normal Voice Samples
First, they tried it out with regular voices from something called the VCTK corpus (just a fancy name for a collection of voice recordings). They used both male and female voices to see how well the system could copy different types of speakers. But here’s where it gets interesting:
- They didn’t just make the computer say a few words. They used a smart AI (called the Gemini API) to come up with whole sentences for the voices to say.
- Then, they played a game of “Guess Who?” They had real people listen to pairs of audio – the original speaker and the AI-generated version – and asked if they thought it was the same person speaking.
The result? A whopping 76% of the time, people thought the AI voice was the real deal. That’s pretty impressive for a system that’s working with voices it’s never heard before!
Here are zero-shot examples utilizing standard reference speech to illustrate instances where the speaker’s voice was recorded prior to any degradation. We showcase the zero-shot capability with samples from the VCTK corpus, with the full list of audio samples available on our GitHub repository:
Reference(Before) and with Zero-shot VT(After)
The Real Challenge: Unique Voices
This is where things get really exciting. Google didn’t just stick to “perfect” voices. They wanted to show how this tech could help people with speech difficulties. They focused on two amazing individuals:
a) Dimitri Kanevsky
A Google scientist with a unique situation. He’s been deaf since he was young and learned to speak English using Russian sounds. This means his speech patterns are pretty unique and can be hard for some people to understand.
What they did:
- Used just 12 seconds of Dimitri’s speech as a reference.
- Created a synthesized version of his voice speaking clearly.
- Asked 10 people who know Dimitri to rate how similar the AI voice was to his real voice.
The result? An impressive 8.1 out of 10!
b) Aubrie Lee
A Googler and disability inclusion advocate with muscular dystrophy, which affects how she speaks.
The process:
- Used about 14 seconds of Aubrie’s speech as a reference.
- Created a synthesized version of her voice.
- Asked Aubrie herself to rate the similarity.
Her verdict? 8 out of 10!
Why These Experiments Matter
These tests show that the technology isn’t just a cool trick – it has real-world potential to help people:
It works with very little data: Just a few seconds of someone’s voice is enough to start with.
It can handle unique speech patterns: This is huge for people with speech difficulties.
It preserves the essence of the original voice: The high similarity scores show it’s not just making a generic “clear” voice, but really capturing what makes each voice unique.
The Bigger Picture: Why This is a Big Deal
Giving Voice to the Voiceless: This tech could help people with speech difficulties communicate more easily without losing their unique voice.
Breaking Language Barriers: Imagine a world where language differences don’t hold us back from connecting with each other.
Personalizing Technology: It shows how AI can adapt to individual needs, not just work for the “average” person.
Advancing AI Understanding: This research pushes forward our ability to understand and replicate human speech, which has implications far beyond just voice copying.
Things to Think About
With great power comes great responsibility, so we need to be careful:
Preventing Misuse: We need strong safeguards to make sure this tech isn’t used to create fake voices for scams or misinformation.
Respecting Cultures: As we cross language barriers, we need to be mindful of cultural differences and sensitivities.
Continuous Improvement: While it’s impressive, there’s still room to make the voices sound even more natural and authentic.
Ethical Use: We need clear guidelines on when and how this technology should be used, especially when it comes to recreating the voices of people who can’t give consent.
Accessibility: We need to ensure this technology is available to those who need it most, not just those who can afford it.
What’s Next on the Horizon?
This is just the beginning. In the future, we might see:
Emotion Transfer: Not just copying voices, but conveying emotions across languages too.
Real-Time Translation: Imagine conversing with someone who speaks a different language, and hearing them in your language instantly.
Personalized AI Assistants: Your digital helper could sound like you or a loved one, making technology feel more personal and relatable.
Preservation of Endangered Languages: This tech could help preserve and teach languages that are at risk of dying out.
Wrapping It Up
Google’s zero-shot cross-lingual voice transfer technology is more than just a cool science experiment. It’s a leap towards breaking down language barriers and giving voices to those who struggle to be understood. As we move forward, it’s exciting to think about how this technology will evolve and what new doors it will open.
But it’s also important to remember that with all new technology, we need to balance excitement with responsibility. We need to make sure this amazing tool is used to help and connect people, not to confuse or deceive.
So, what do you think? Can you imagine how this might change lives? Or do you see any challenges we haven’t considered? The future of voice technology is here, and it’s speaking in many voices – maybe even yours!
Discover more from Techknr
Subscribe to get the latest posts sent to your email.

